YOLO 目标检测系列算法的发展历程与版本对比
引言
在计算机视觉领域,目标检测是一个永恒的核心课题。从早期的滑动窗口+手工特征,到后来的两阶段检测范式(R-CNN系列),再到如今单阶段算法的全面崛起,这个领域经历了翻天覆地的变化。而在单阶段检测算法中,YOLO(You Only Look Once)系列无疑是最具影响力、工程化最成功的代表。
从2016年Joseph Redmon发布YOLOv1至今,YOLO系列已经走过了十个年头,迭代了12个主要版本。这期间,不仅有原作者的天才设计,还有来自工业界和学术界的持续贡献,形成了一个蓬勃发展的生态系统。本文将系统梳理YOLO系列的发展脉络,对比各版本的核心特性与性能,并给出实际场景下的选型建议。
发展历程:从天才idea到工业标准
奠基期:YOLOv1(2016)
2016年,Joseph Redmon的一篇论文《You Only Look Once: Unified, Real-Time Object Detection》彻底改变了目标检测的格局。在此之前,两阶段算法(如Faster R-CNN)虽然精度较高,但推理速度较慢,难以满足实时需求。
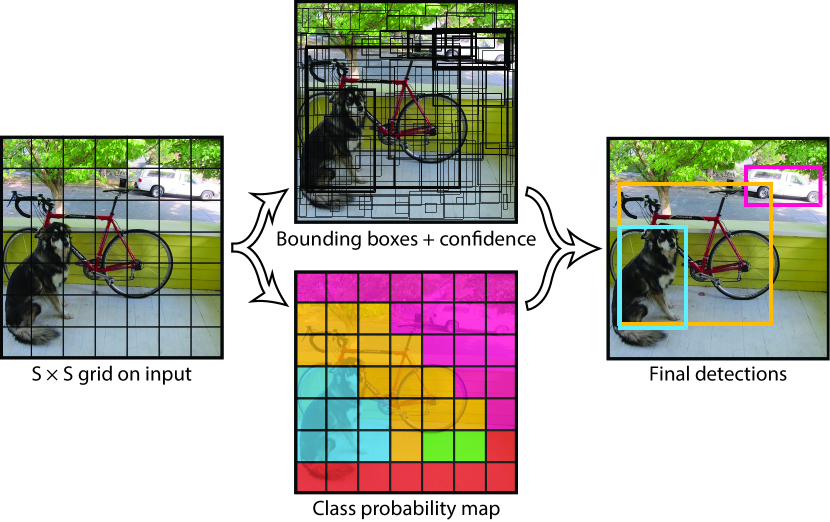
Figure 2 from YOLOv1 (Redmon et al., 2016):检测编码为 S×S×(B·5+C) 张量,每个格子负责预测中心点落入其中的目标。
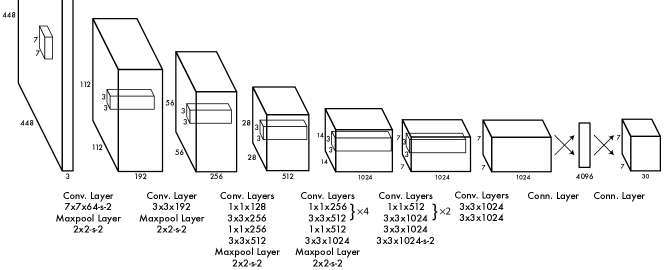
Figure 3 from YOLOv1:网络由 24 层卷积层后接 2 层全连接层组成,交替使用 1×1 卷积降维。
核心突破:
- 首次将目标检测视为回归问题,直接从图像像素回归出边界框坐标和类别概率
- 单网络端到端训练,无需区域提议(Region Proposal)阶段
- 将图像划分为S×S网格,每个网格负责预测中心点落在其中的目标
点评:
YOLOv1的设计哲学极具颠覆性——“看一次就够了”。这种简洁性带来了极快的推理速度,但也存在明显局限:对小目标和密集目标检测效果较差,边界框定位不够精确。然而,它为后续所有YOLO版本奠定了”单阶段、实时、端到端”的基调。
进化期:YOLOv2/YOLO9000(2017)
Redmon很快意识到v1的不足,并在次年推出了YOLOv2,同时还发布了一个野心勃勃的版本——YOLO9000,能检测超过9000类物体。
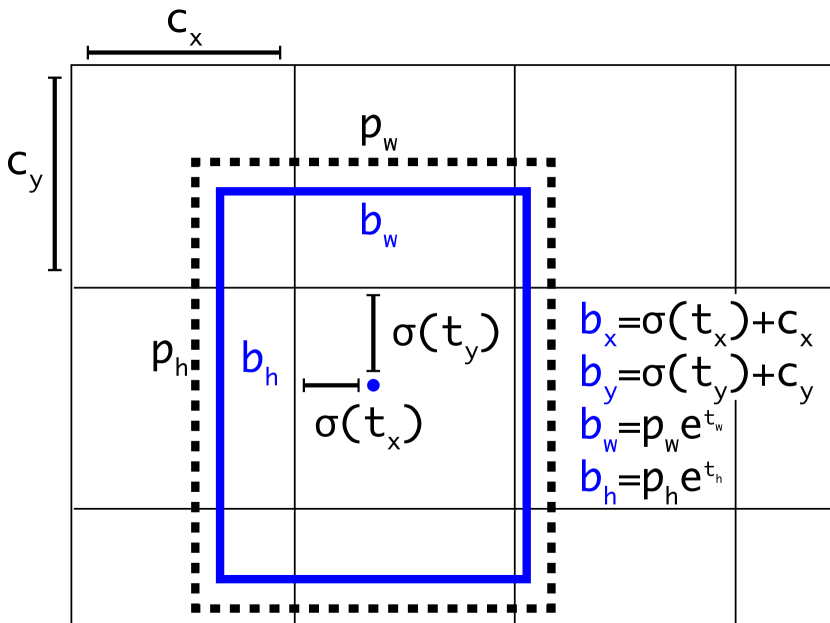
Figure 3 from YOLOv2/YOLO9000 (Redmon & Farhadi, 2017):预测宽高相对于聚类中心的偏移,用 sigmoid 将中心坐标限制在当前格子范围内。
核心改进:
- 引入Anchor Box(借鉴Faster R-CNN),大幅提升边界框召回率
- 添加Batch Normalization,加速收敛并提升模型稳定性
- 采用多尺度训练,让模型适应不同分辨率的输入
- 使用Darknet-19作为骨干网络,平衡精度与速度
- YOLO9000:提出了一种联合训练方法,能同时利用检测数据集和分类数据集
点评:
YOLOv2是一次非常务实的改进。Anchor Box的引入是关键——它解决了v1中”每个网格只能预测一个目标”的限制。多尺度训练则让模型变得更加鲁棒。YOLO9000的联合训练思路很有想象力,虽然在当时实用性有限,但为后来的开放词汇检测埋下了伏笔。
成熟期:YOLOv3(2018)
YOLOv3是Redmon的最后一个主要版本,也是整个系列中最经典、最具生命力的版本之一。即使在今天,仍有大量项目基于v3进行开发。
核心改进:
- 提出Darknet-53骨干网络,更深的网络结构带来更强的特征提取能力
- 实现多尺度预测(FPN的雏形),在3个不同尺度的特征图上进行检测,有效解决了小目标检测问题
- 每个预测点预测3个Anchor Box,进一步提升召回率
- 用逻辑回归替代softmax进行分类,支持多标签分类
点评:
YOLOv3的设计体现了”实用主义”的巅峰。Darknet-53借鉴了ResNet的残差思想,既保证了深度又避免了梯度消失。多尺度预测是另一个关键改进——它让模型能够同时捕捉不同大小的目标,这是v3相比v2最大的提升。Redmon在发布v3后不久便宣布退出计算机视觉领域,但他留下的v3却成为了工业界的”常青树”。
转折期:YOLOv4(2020)
Redmon离开后,YOLO系列的火炬传到了Alexey Bochkovskiy手中。2020年,他发布了YOLOv4,这是YOLO系列发展史上的一个重要转折点。
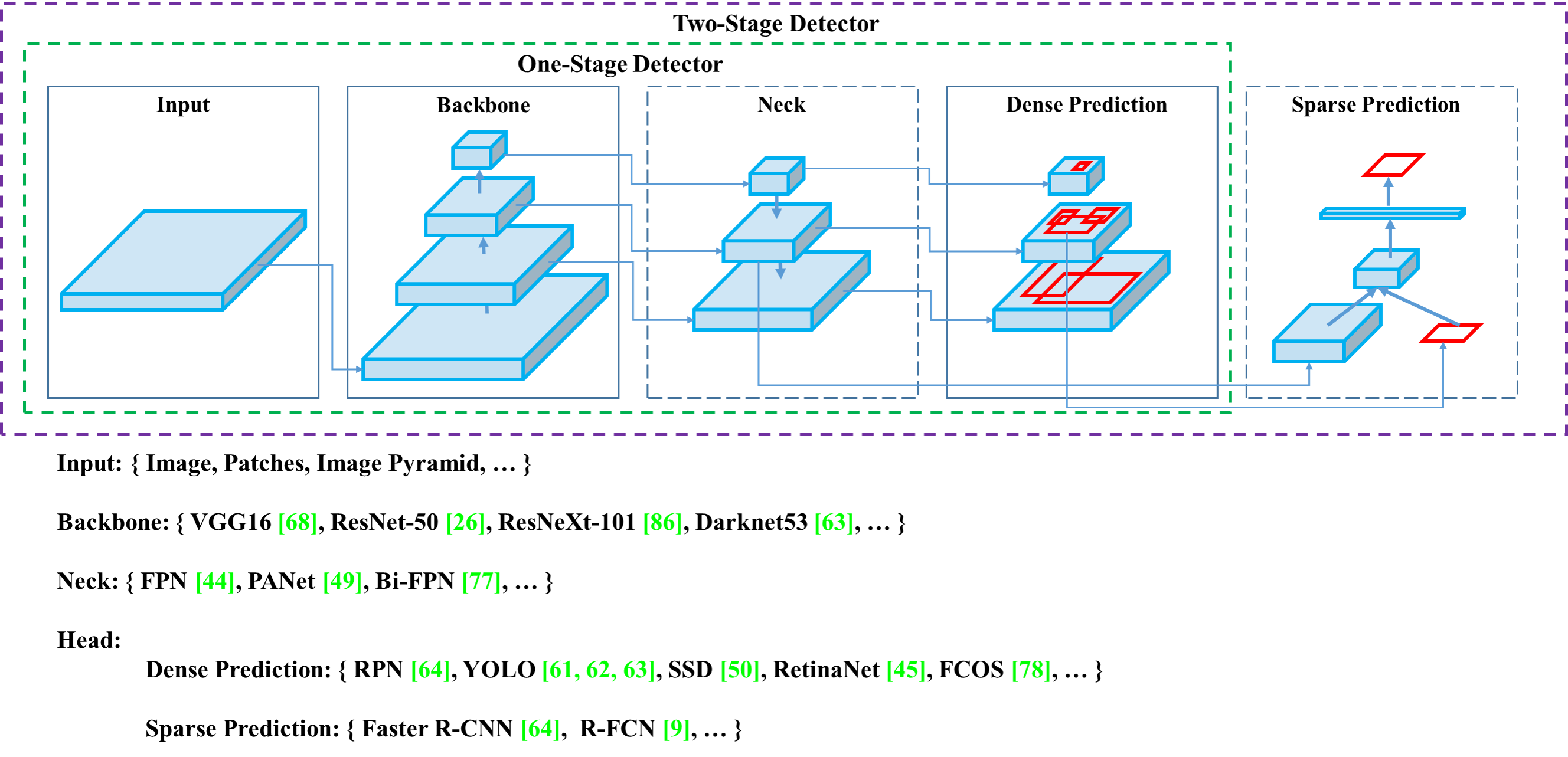
Figure 2 from YOLOv4 (Bochkovskiy et al., 2020):完整检测器由 Input、Backbone、Neck、Prediction Head 四部分组成。
核心改进:
- 引入CSP(Cross Stage Partial)结构,优化梯度流动,减少计算量
- 提出Mosaic数据增强,将4张图片拼接成一张,极大丰富了背景信息
- 使用PANet(Path Aggregation Network) 替代FPN,增强特征融合能力
- 采用CIoU Loss,同时考虑边界框的重叠面积、中心点距离和长宽比
- 加入大量训练技巧:余弦退火学习率、label smoothing等
点评:
YOLOv4标志着YOLO系列从”个人作品”向”社区协作”的转变。AlexeyAB没有追求革命性的架构创新,而是将当时各种有效的技巧整合在一起——CSP、Mosaic、PANet、CIoU……这些改进虽然单独来看都不是首创,但组合起来却产生了显著的效果。Mosaic增强尤其聪明,它用一种极其简单的方式大幅提升了模型的鲁棒性。
工程化:YOLOv5(2020)
就在YOLOv4发布后不久,Ultralytics公司推出了YOLOv5。这个版本在学术界引发了一些争议(因为没有对应的论文),但在工程界却获得了巨大的成功。
核心改进:
- 完全迁移至PyTorch框架,告别了Darknet的晦涩代码
- 提出Focus模块,对特征图进行切片再拼接,减少下采样的信息损失
- 完善的工程生态:丰富的预训练模型、简单的API、完整的部署工具链
- 灵活的模型缩放策略:通过深度因子和宽度因子控制模型大小(Nano/Small/Medium/Large)
点评:
YOLOv5的最大贡献不在于算法创新,而在于工程化。Ultralytics将YOLO从一个”算法”变成了一个”产品”。PyTorch的迁移让更多开发者能够轻松上手,完善的工具链让部署变得前所未有的简单。v5的成功告诉我们:在工业界,有时好的工程实现比论文中的新点子更重要。
工业化:YOLOv6(2022)
2022年,美团视觉智能部发布了YOLOv6,这是国内工业界对YOLO系列的重要贡献。v6的设计目标非常明确——面向端侧部署。
核心改进:
- 引入RepVGG重参数化技术,训练时使用多分支结构提升精度,推理时合并为单分支提升速度
- 专为端侧优化的骨干网络设计
- 提供更丰富的量化支持
点评:
YOLOv6代表了YOLO系列在工业化落地方向上的深入探索。重参数化是一个极具实用价值的技术——它让我们能够”鱼与熊掌兼得”:训练时的高精度和推理时的高效率。v6的出现也说明,YOLO系列已经不再是少数人的游戏,而是全球工业界共同参与的平台。
架构创新:YOLOv7(2022)
同样是2022年,Chien-Yao Wang等人发布了YOLOv7。这个版本在学术界获得了很高的评价,被认为是”学术派”YOLO的代表。
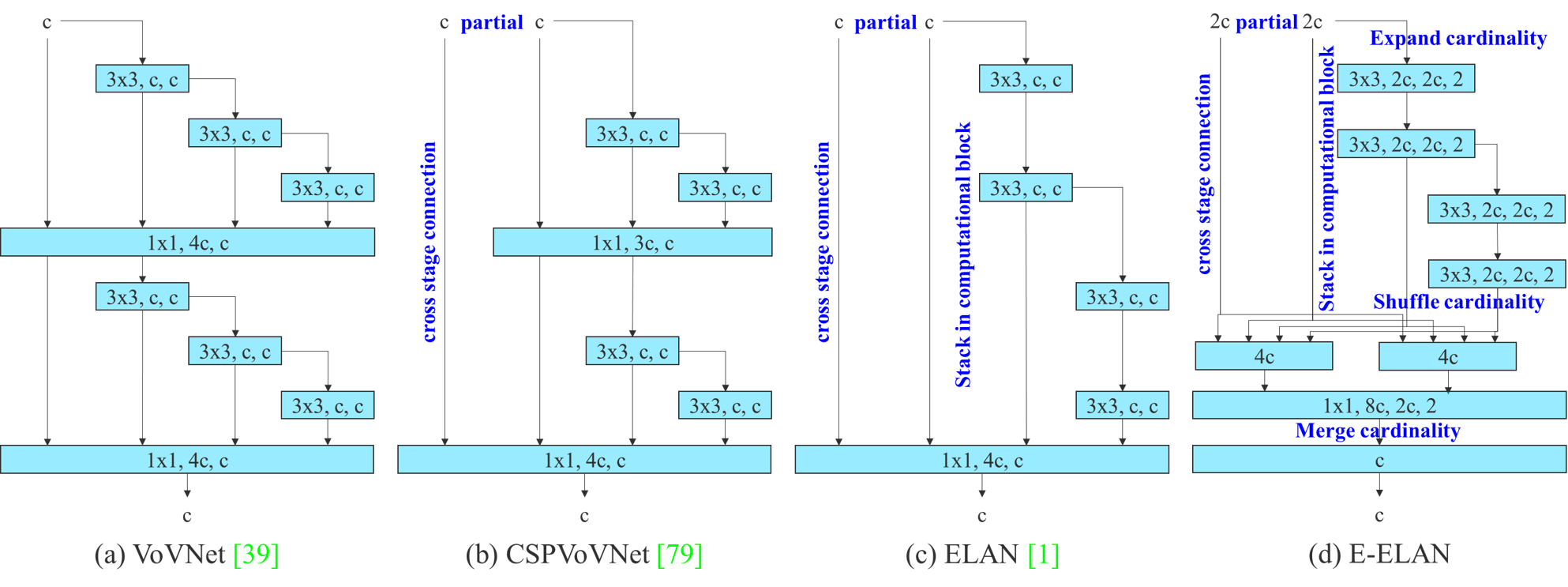
Figure 2 from YOLOv7 (Wang et al., 2022):E-ELAN 不改变原有梯度传输路径,用 group conv + cardinality shuffle 增强特征表达能力。
核心改进:
- 提出E-ELAN(Extended Efficient Layer Aggregation Network),通过控制最短最长梯度路径来增强梯度流动
- 深入探索模型重参化策略,提出了更科学的重参化方法
- 使用动态标签分配策略,优化训练过程
点评:
YOLOv7是一次扎实的架构创新。E-ELAN的设计体现了对梯度流动的深刻理解——它让网络能够更深、更高效地学习。v7证明了:即使在YOLO这样已经高度优化的架构上,仍然有通过精细设计提升性能的空间。
Anchor-Free:YOLOv8(2023)
2023年,Ultralytics带着YOLOv8强势回归。这是Ultralytics继v5之后的又一力作,也是YOLO系列的一次架构跃迁。
核心改进:
- 解耦头:将分类和检测头分开,让两个任务各自优化
- Anchor-Free:抛弃了Anchor Box的设计,直接预测目标的中心点和宽高
- 任务统一化:在同一框架下支持检测、分割、姿态估计等多种任务
- 新的骨干网络和Neck设计
点评:
YOLOv8是一次勇敢的架构升级。解耦头的设计非常直观——分类和检测本来就是两个不同的任务,用不同的头来处理是合理的。Anchor-Free则进一步简化了检测流程,减少了超参数的数量。更重要的是,v8开始向”多任务统一”的方向迈进,这是计算机视觉的一个重要趋势。
信息可编程:YOLOv9(2024.02)
2024年2月,WongKinYiu(v4、v7的作者之一)发布了YOLOv9。这个版本的核心思想是”可编程梯度信息”。
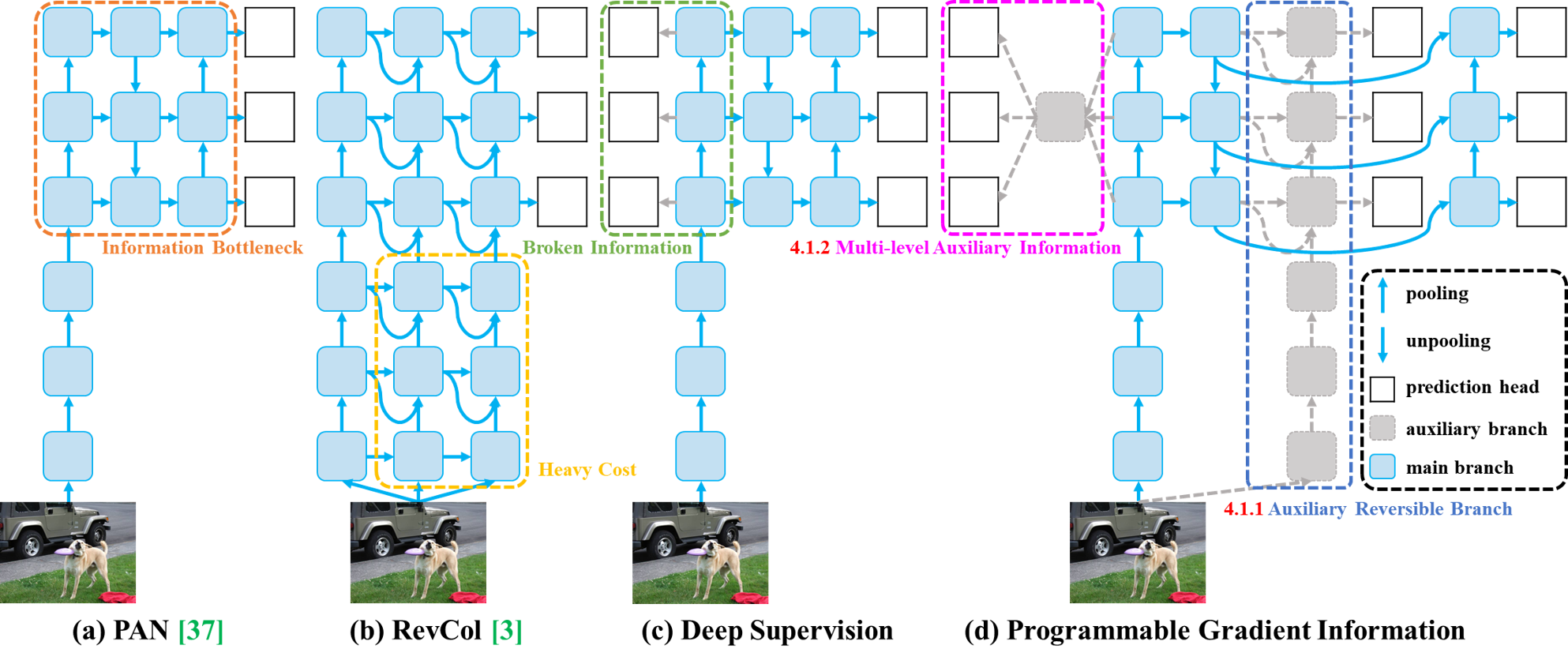
Figure 3 from YOLOv9 (Wang et al., 2024):PGI 由主分支(推理用)、辅助可逆分支(提供可靠梯度)、多级辅助信息三部分构成。
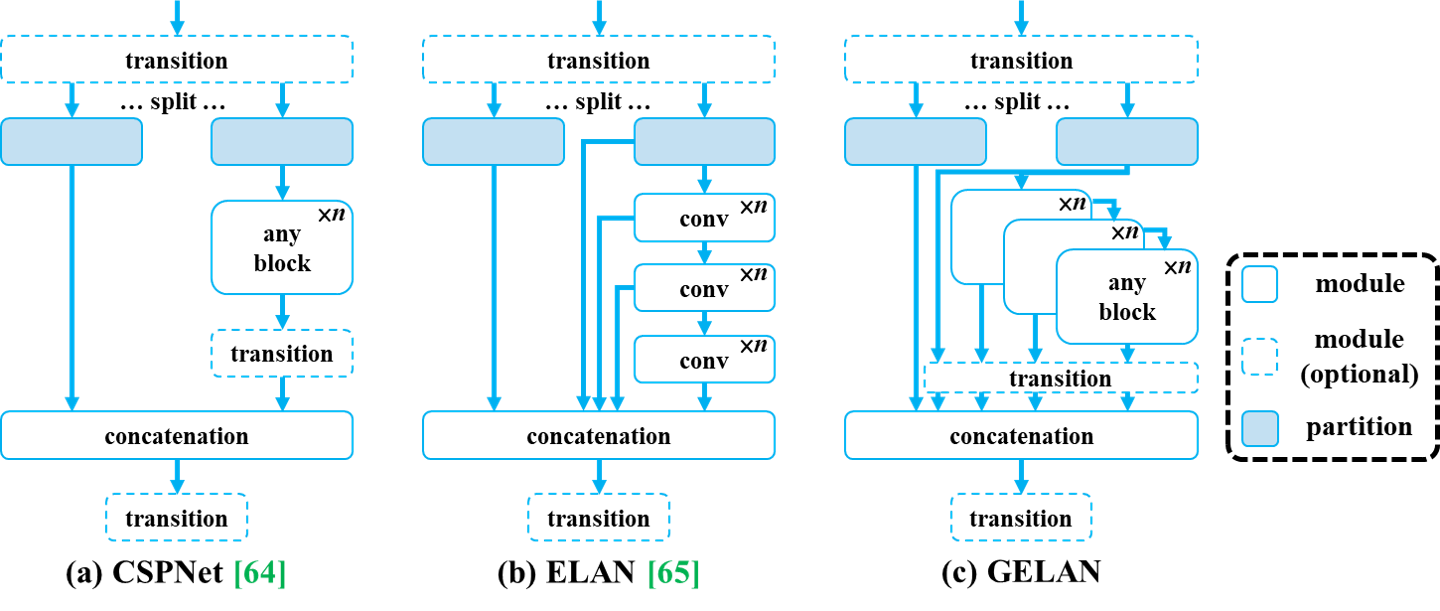
Figure 4 from YOLOv9:GELAN 将 CSPNet 与 ELAN 结合,可插入任意计算块,在轻量化的同时保持高精度。
核心改进:
- 提出PGI(Programmable Gradient Information),解决深层网络训练时的信息丢失问题
- 设计GELAN(Generalized Efficient Layer Aggregation Network),在保持轻量化的同时提升精度
- 重新思考特征融合策略,确保梯度能有效流动
点评:
YOLOv9的设计哲学很有深度——它关注的是”信息如何在网络中流动”。PGI的核心思想是:在深层网络中,梯度信息会逐渐丢失,我们需要一种方式来”编程”这些信息,让它们能够有效地传播。v9在COCO数据集上取得了当时的最高精度,证明了这种思路的有效性。
端到端:YOLOv10(2024.05)
2024年5月,清华大学的团队发布了YOLOv10。这个版本的目标很明确:实现真正的”端到端”检测,去掉NMS后处理。
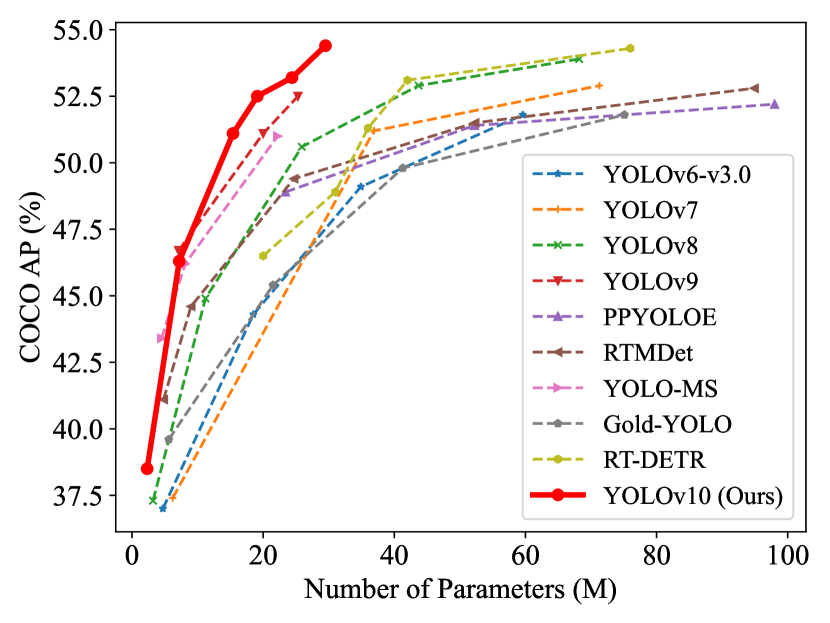
Figure 2 from YOLOv10 (Wang et al., 2024):训练时同时优化两条分支,推理时只用一对一分支,天然无重复预测,无需 NMS。
核心改进:
- NMS-Free:通过双标签分配策略,让模型直接输出无冗余的检测结果,无需NMS后处理
- 优化的模型架构,在保持精度的同时提升效率
- 更低的延迟,特别适合高密度检测场景
点评:
NMS是目标检测流程中一个”令人讨厌”的步骤——它会带来额外的延迟,而且不是可微的,无法在训练中优化。YOLOv10通过巧妙的标签分配策略去掉了NMS,实现了真正的”端到端”。这在高密度场景下特别有价值,因为NMS的延迟往往会随着目标数量的增加而增加。
全能王:YOLOv11(2024.09)
2024年9月,Ultralytics发布了YOLOv11。这个版本将”多任务统一”推向了新的高度。
核心改进:
- 提出C3k2/C2PSA架构,进一步优化特征提取和融合
- 统一支持**检测、分割、姿态估计、OBB(旋转框)**等多种任务
- 更完善的量化和部署工具链
- 更好的小目标检测能力
点评:
YOLOv11代表了”大一统”的趋势。在一个框架下支持多种任务,不仅降低了开发成本,也让任务之间的信息能够相互促进。v11的工程生态也是所有YOLO版本中最完善的——从训练到部署,从量化到加速,几乎所有环节都有现成的工具。
注意力时代:YOLOv12(2025.02)
2025年2月,Ultralytics发布了最新的YOLOv12。这个版本标志着YOLO系列正式进入”注意力时代”。

Figure 2 from YOLOv12 (Tian et al., 2025):Area Attention 将特征图等分为 l 个区域(默认4),在区域内做自注意力,兼顾大感受野与线性复杂度。

Figure 3 from YOLOv12:R-ELAN(Residual ELAN)通过残差连接解决深层网络梯度衰减,确保训练稳定性。
核心改进:
- 引入Area Attention,将自注意力复杂度从O(n²)降至线性,通过划分水平/垂直区域来实现高效的全局建模
- 设计R-ELAN,在GELAN基础上添加残差连接,改善梯度流动
- 集成FlashAttention优化,让注意力操作在实时推理中可用
- 平衡全局建模和局部特征提取,在精度和效率之间取得更好的平衡
点评:
YOLOv12是一次大胆的尝试——将Transformer中的自注意力机制引入到实时检测架构中。Area Attention的设计非常巧妙:它既保留了自注意力的全局建模能力,又通过区域划分将复杂度控制在可接受范围内。v12的出现标志着:注意力机制不再只是NLP和大模型的专利,它正在全面进入实时计算机视觉领域。
版本对比:数据说话
为了更直观地对比各版本的性能,我们整理了近年来主要版本在COCO val2017数据集上的表现。
精度对比(mAP 50-95)
| 规格 | YOLOv8 | YOLOv9 | YOLOv10 | YOLOv11 | YOLOv12 |
|---|---|---|---|---|---|
| Nano | 37.3 | 38.3 | 38.5 | 39.5 | 38.0 |
| Small | 44.9 | 46.8 | 46.3 | 47.0 | ~47.5 |
| Medium | 50.2 | 51.4 | 51.3 | 51.5 | ~52.0 |
| Large | 52.9 | 53.0 | 53.2 | 53.4 | ~54.0 |
| XLarge | 53.9 | 55.6 | 54.4 | 54.7 | 55.2 |
从精度数据来看,整体呈现稳步提升的趋势。值得注意的是:
- YOLOv9-E在XLarge规格下取得了55.6的最高精度,这在当时是非常出色的成绩
- YOLOv11在中低规格下表现突出,Nano规格比v8高出2.2个mAP
- YOLOv12在Small以上规格中表现最好,说明Area Attention在较大模型上更有优势
参数量与效率对比(X规格)
| 版本 | 参数量 (M) | GFLOPs | mAP 50-95 |
|---|---|---|---|
| YOLOv8-X | 68.2 | 257.8 | 53.9 |
| YOLOv9-E | 58.1 | 192.5 | 55.6 |
| YOLOv10-X | 29.5 | 160.4 | 54.4 |
| YOLOv11-X | 56.9 | 194.9 | 54.7 |
| YOLOv12-X | 57.5 | 138.0 | 55.2 |
效率数据更有意思:
- YOLOv10-X的参数量只有29.5M,是所有X规格中最小的,这得益于NMS-Free设计带来的简化
- YOLOv12-X的GFLOPs只有138.0,是所有版本中最低的,同时精度却达到了55.2——这充分体现了Area Attention的效率优势
- YOLOv9-E在参数量和GFLOPs都低于v8-X的情况下,精度反而更高,说明PGI和GELAN的设计非常高效
重要变体:百花齐放
除了主要版本外,YOLO生态中还涌现出了许多重要的变体,它们针对不同的应用场景进行了优化。
YOLO-World(腾讯AILab)
核心特点:开放词汇检测,文本驱动,无需重训
点评:YOLO-World是一个非常有想象力的作品。它将YOLO的实时能力与CLIP的开放词汇能力结合起来,让用户能够通过文本描述来检测任意类别的物体,而无需重新训练模型。这种”即插即用”的特性在很多实际场景中非常有用,比如工业质检中的缺陷检测(缺陷类型往往是多样化且难以预定义的)。
YOLO-NAS(Deci AI)
核心特点:NAS架构搜索,INT8量化友好
点评:YOLO-NAS代表了”自动化设计”的方向。Deci AI使用神经架构搜索(NAS)技术,自动设计出更高效的架构。更重要的是,他们在搜索过程中就考虑了量化友好性,使得YOLO-NAS在INT8量化下的性能损失非常小。这对于边缘设备部署来说非常有价值。
RT-DETR(百度)
核心特点:Transformer实时检测,mAP 53-54.8
点评:RT-DETR是Transformer在实时检测领域的成功尝试。它证明了:只要设计得当,Transformer架构也能达到实时性能。RT-DETR的NMS-Free设计也很有特色——它通过匈牙利算法直接进行一对一匹配,避免了NMS带来的延迟。
Gold-YOLO(华为诺亚)
核心特点:Gather-Distribute聚合分发机制
点评:Gold-YOLO提出了一种新的特征融合思路——Gather-Distribute。与传统的FPN/PANet不同,它先将所有尺度的特征聚合到一起,然后再分发给各个尺度。这种”先聚后分”的方式能够更有效地利用跨尺度信息,在小目标检测上表现尤其突出。
场景选型建议
说了这么多,到底该选哪个版本呢?我们根据不同的需求给出以下建议:
| 需求 | 推荐 | 原因 |
|---|---|---|
| 嵌入式/边缘设备 | YOLOv11-N/S | 参数最小,量化工具链成熟 |
| 极低延迟(服务器) | YOLOv10-S/M | NMS-Free,高密度场景延迟优势 |
| 生产环境通用 | YOLOv11-M | 生态最完善,多任务支持 |
| 学术/高精度 | YOLOv9-E 或 YOLOv12-X | 精度最高,架构最前沿 |
| 动态类别检测 | YOLO-World | 开放词汇,文本驱动 |
具体场景分析
1. 嵌入式/边缘设备
如果你的部署目标是嵌入式设备(如树莓派、Jetson Nano、手机等),那么YOLOv11的Nano或Small规格是最佳选择。v11在小模型上的优化非常出色,而且Ultralytics提供了完善的量化和部署工具链,支持ONNX、TensorRT、NCNN等多种推理框架。
2. 极低延迟(服务器)
如果你需要在服务器上运行极低延迟的检测(比如实时视频流分析、自动驾驶的感知系统),那么YOLOv10是更好的选择。v10的NMS-Free设计在高密度场景下特别有优势——随着目标数量的增加,v10的延迟增长比其他版本慢得多。
3. 生产环境通用
对于大多数生产环境的应用场景,YOLOv11-M是最稳妥的选择。它的精度足够高,速度足够快,而且生态最完善——从训练到部署,从数据增强到模型量化,几乎所有环节都有现成的工具。此外,v11的多任务支持(检测、分割、姿态、OBB)也让它能够应对更多样化的需求。
4. 学术/高精度
如果你在做学术研究,或者对精度有极高的要求(比如医疗影像分析、卫星图像解读),那么YOLOv9-E或YOLOv12-X是最佳选择。v9-E在XLarge规格下取得了55.6的mAP,是目前所有YOLO版本中最高的。v12-X则在精度和效率之间取得了更好的平衡,而且它的Area Attention设计也很有研究价值。
5. 动态类别检测
如果你需要检测的类别是动态的、无法预定义的(比如工业质检中的缺陷检测、开放环境下的监控),那么YOLO-World是唯一的选择。它让你能够通过文本描述来定义检测类别,无需重新训练模型——这种灵活性在很多实际场景中是不可替代的。
YOLOv12技术亮点深度解析
作为YOLO系列的最新版本,YOLOv12有几个技术亮点值得我们深入探讨。
Area Attention:线性复杂度的全局建模
自注意力机制(Self-Attention)的最大问题是复杂度——它的计算量是O(n²),其中n是token的数量。对于高分辨率图像来说,这是不可接受的。
YOLOv12提出的Area Attention巧妙地解决了这个问题。它的核心思想是:
- 将特征图划分为水平区域和垂直区域
- 在每个区域内进行自注意力计算
- 这样既保留了一定的全局建模能力,又将复杂度从O(n²)降至线性
点评:Area Attention是一种非常”工程化”的创新。它没有追求理论上的完美,而是在精度和效率之间找到了一个很好的平衡点。通过区域划分,它既避免了全局注意力的高昂计算成本,又比纯粹的局部注意力拥有更大的感受野。
R-ELAN:改善梯度流动
YOLOv12在GELAN(来自YOLOv9)的基础上,添加了残差连接,形成了R-ELAN。
设计思路:
- 保留GELAN的高效特征聚合能力
- 添加残差连接,确保梯度能够直接传播到较早的层
- 这种设计让网络能够更深,同时避免梯度消失
点评:残差连接(Residual Connection)并不是什么新东西,但它的有效性已经被无数次证明。YOLOv12将它和GELAN结合起来,是一次”简单但有效”的改进。这也说明:在架构设计中,有时不需要追求花哨的新东西,把已有的技巧用好就足够了。
FlashAttention:让注意力在实时推理中可用
FlashAttention是近年来最重要的深度学习优化之一。它通过重新组织计算顺序,大幅提升了自注意力的计算速度和内存效率。
YOLOv12集成了FlashAttention优化,这使得Area Attention在实时推理中变得可用。没有FlashAttention,即使Area Attention的理论复杂度很低,实际运行速度可能也无法接受。
点评:好的算法需要好的实现才能发挥价值。FlashAttention就是一个典型的例子——它不是改变算法本身,而是改变算法的实现方式,却带来了巨大的性能提升。YOLOv12的作者们显然很清楚这一点,他们及时地将最新的优化技巧整合到了架构中。
结语:YOLO系列的启示
回顾YOLO系列十年的发展历程,我们可以得到很多启示:
1. 简洁性是工程成功的关键
YOLOv1的成功,很大程度上在于它的简洁——“看一次就够了”。这种简洁性让它容易理解、容易实现、容易优化。在工程领域,简单的方案往往比复杂的方案更有生命力。
2. 架构创新和工程化同样重要
YOLOv3、v7、v9、v12代表了架构创新的方向,而v5、v6、v8、v11则代表了工程化的方向。这两条线都很重要——没有架构创新,就没有性能的突破;没有工程化,再好的算法也难以落地。
3. 社区协作是技术进步的加速器
Redmon在的时候,YOLO是个人作品;Redmon离开后,YOLO变成了社区协作的平台。AlexeyAB、Ultralytics、美团、清华大学……来自全球的开发者和研究者共同推动着YOLO系列的发展。这种社区协作模式大大加速了技术进步。
4. 趋势总是会到来的
从两阶段到单阶段,从Anchor-Based到Anchor-Free,从CNN到Attention……这些趋势在早期都充满争议,但最终都成为了主流。YOLO系列的发展历程告诉我们:不要抗拒趋势,要主动拥抱趋势,在合适的时候将新的技术整合到自己的架构中。
未来,YOLO系列会走向何方?我们可以期待:更好的多任务统一,更强的开放词汇能力,更高效的注意力机制,更完善的工具链……但有一点是肯定的:YOLO系列还会继续发展,继续推动计算机视觉的进步。
对于我们这些使用者来说,最重要的不是追最新的版本,而是根据自己的需求选择合适的版本,把它用好。毕竟,在实际项目中,把一个模型用好比用一个”最好”的模型更重要。